자격증 준비하면서 내가 이해하기 편하게, 다시 보기 좋게 정리하는 SQLD의 기본 내용 (자격증 상세 내용은 아래)
https://www.dataq.or.kr/www/sub/a_03.do
데이터자격시험
SQL 전문가(SQLP*, SQL Professional)란 데이터베이스와 데이터모델링에 대한 지식을 바탕으로 데이터를 조작하고 추출하는데 있어서 정확하고 최적의 성능을 발휘하는 SQL을 작성할 수 있고, 이를 토대
www.dataq.or.kr

데이터자격 검정 사이트에 나와있는 1과목의 데이터 모델링과 성능에 해당하는 내용을 정리한 것
데이터 모델과 성능
정규화
- 데이터의 정확성과 일관성을 유지하고 보장하는 데이터 정합성을 위한 엔터티를 작은 단위로 분리하는 과정
- 중복을 제거하여 이상 현상을 방지하기 위한 기술
정규화의 특징
- 데이터 중복성 제거
- 정규화를 진행할수록 엔터티 증가
- 데이터 입력, 수정, 삭제 성능 향상
- JOIN으로 인한 성능 저하 발생할 수 있음
제 1 정규화
- 모든 속성은 반드시 1개의 값만 가져야 한다는 특성
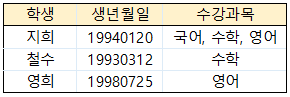
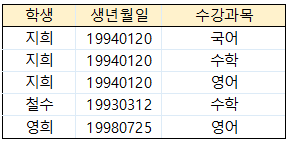
위 테이블에서 지희의 수강과목 컬럼에서 3개의 속성값을 갖고 있음 → 이를 쪼개어 원자값을 갖도록 아래와 같이 쪼개주는 것
제 2 정규화
- 엔터티의 모든 일반속성은 반드시 모든 주식별자에 종속되어야 한다는 특성
- 기본 키중에 특정 칼럼에만 종속된 칼럼이 존재할 경우 2차 정규형에 위배

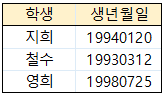
제 1 정규화를 거친 테이블에서 중복 데이터로 인해 학생과 생년월일로 구분할 수 없음
학생과 수강과목을 합친 [학생, 수강과목] 키로 각각을 구별 할 수 있음 (학생과 수강과목을 알면 생년 월일이 자연스레 나옴)
생년월일은 학생에 종속되어 있어, 학생을 알면 생년월일을 바로 알 수 있음 (2차 정규형 위배)
[학생정보] 테이블
[과목] 테이블

위 와 같이 테이블을 나누는 과정
제 3 정규화
- 제 2 정규형을 만족하는 상태에서 이행 함수 종속을 제거하는 정규화 과정
- 주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없음
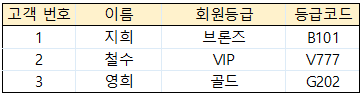
고객 번호를 알면 각 칼럼의 속성 값들을 알 수 있음
회원 등급은 고객 번호에 의해 결정되어지고, 등급코드는 회원 등급에 의해 결정되는 구조가 되어있음
→ 등급코드 ⊂ 회원등급 (X ⊂ Y), 회원 등급 ⊂ 고객번호 (Y ⊂ Z) 이어서
등급코드 ⊂ 고객번호(X ⊂ Z)가 되어버리면 이행 함수 종속이 발생. 이를 제거하는 과정이 제 3정규화
[고객정보] 테이블

[등급] 테이블

위 와 같이 테이블을 나누는 과정
반정규화
- 데이터의 조회 성능을 향상 시키기 위해 데이터의 중복을 허용하거나 데이터를 그룹핑하는 과정
- 조회 성능은 향상 될 수 있으나 입력, 수정, 삭제 성능이 저하될 수 있음
- 데이터 정합이 발생 및 데이터 무결성이 저해될 수 있음
- 반정규화는 정규화가 끝난 후 거치게 됨
테이블 병합
1:1 관계 테이블 병합 과정

1:M 관계 테이블 병합 과정
- 중복된 데이터가 생길 수 있음
- 데이터 검색은 간편하지만 레코드증가로 인해 처리량이 증가
- 제약 조건을 설계하기 어려움
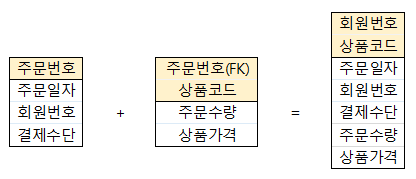
테이블 분할
테이블 수직 분할
- 엔터티의 일부 속성 별도의 엔터티로 분할(1:1 관계)
- 수직 분할시 한 개의 블록에 더 많은 인스턴스를 저장
- 속성의 사용 빈도나 속성값의 NULL 여부를 기준으로 분할

테이블 수평 분할
- 엔터티의 인스턴스를 특정 기준으로 별도의 엔터티로 분할
- 데이터베이스의 파티셔닝 기법을 주로 이용
- 테이블 수평 분할을 할 경우 관계가 없는 다수의 테이블이 생성됨

테이블 추가
- 중복 테이블 추가 : 데이터의 중복을 감안하더라도 성능상 필요하다고 판단되는 경우 별도 엔터티 추가
- 통계 테이블 추가
- 이력 테이블 추가
- 부분 테이블 추가
컬럼 반정규화
- 중복 칼럼 추가 : 업무 프로세스상 JOIN이 필요한 경우가 많아 컬럼을 추가하는 것이 성능적으로 유리할 경우
- 파생 컬럼 추가 : 프로세스 수행 시 부하가 염려되는 계산값을 미리 컬럼으로 추가하여 보관하는 방식
- 이력 테이블 컬럼 추가 : 대량의 이력 테이블을 조회할 때 속도가 느려질 것을 대비하여 조회 기준이 될 것으로 판단되는 컬럼을 미리 추가해 놓는 방식
중복관계 추가
업무 프로세스상 JOIN이 필요한 경우가 많아 중복 관계를 추가하는 것이 성능 측면에서 유리할 경우 고려
기타
트랜젝션 : 데이터를 조작하기 위한 하나의 논리적 작업 단위
NULL : 값이 없음 표시
대용량 데이터에 따른 성능
대용량 데이터 발생으로 인한 문제점
- 대량의 데이터가 하나의 테이블에 집약되어 있고 하나의 하드웨어 공간에 저장되면 성능 저하 발생
- 하나의 테이블에 많은 컬럼이 존재하는 경우 성능 저하 발생
- 대량의 데이터가 저장된 테이블의 인덱스도 인덱스의 트리구조가 너무 커져 DML처리를 할 때 성능이 저하
로우체이닝
row의 길이가 너무 길어져 데이터 블록 하나에 데이터가 모두 저장되지 않고 두 개 이상의 블록에 걸쳐 하나의 로우가 저장된 형태
로우 마이그레이션
데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식
대용량 데이터 저장·처리 방법 (파티셔닝)
- 특정값 지정 파티셔닝 : 날짜나 숫자 값으로 분리가 가능하고 영역별 트랜잭션 분리 가능시 적용
- 범위 파티셔닝 : 핵심적 코드 값 등으로 PK가 구성되어있고, 대량의 데이터가 있는 테이블이라면 적용 가능
- 해쉬 파티셔닝 : 지정된 해쉬 알고리즘을 적용하여 테이블 분리
- 복합 파티셔닝 : 관계를 분할하여 파티셔닝하는 기법
DB 구조와 성능
슈퍼 타입과 서브타입 데이터 모델
- 슈퍼 타입 : 공통의 부분
- 서브 타입 : 공통으로부터 상속받아 다른 엔티티와 차이가 있는 속성
성능 저하의 원인
- 트랜잭션은 일괄처리, 테이블은 개별로 유지되어 Union 연산에 의한 성능 저하
- 트랜잭션은 서브타입 개별로 처리, 테이블은 하나로 통합되어 성능 저하
- 트랜잭션은 슈퍼+서브타입을 공통으로 처리, 테이블은 개별로 유지하거나 하나로 집약되어 성능 저하
PK · FK 칼럼 순서와 성능
- 인덱스 중요성 : 데이터 조작시 가장 효과적으로 처리될 수 있도록 접근 경로 제공
- PK·FK 설계 중요성 : 데이터에 접근시 접근경로 제공, 설계 마지막에 칼럼 순서 조정
- PK 순서의 중요성 : 물리적인 모델링 단계에서 생성된 PK 이외에 상속 PK 순서 주의 필요
- FK 순서의 중요성 : 조인의 경로 제고 역할 수행 및 조회 조건 고려하여 반드시 인덱스를 생성
분산 데이터베이스에 따른 성능
분산 데이터베이스
빠른 네트워크 환경을 이용하여 데이터베이스를 여러 지역에서 노드로 위치시켜 사용성과 성능을 극대화 시킨 것
분산 데이터베이스의 투명성
- 분할 투명성 : 하나의 논리적 관계를 여러 단편으로 분할하고 여러 사이트에 저장
- 위치 투명성 : 사용하려는 데이터의 저장 장소를 명시하지 않으며, 위치 정보가 시스템 카탈로그에 유지 되어야함
- 지역사상 투명성 : 지역DBMS와 물리적 DB사이 맵핑 보장
- 중복 투명성 : 데이터베이스 객체가 여러 사이트에 중복되어 있는지 확인할 필요 없음
- 장애 투명성 : 구성요소의 장애에 무관하게 트랜잭션의 원자성 유지
- 병행 수행성 : 다수 트랜잭션 동시 수행 시 결과의 일관성 유지
분산 데이터베이스의 장·단점
- 장점
- 지역 자치성, 점증적 시스템 용량 확장
- 신뢰성, 가용성, 효용성, 융통성
- 빠른 응답 속도와 통신비용 절감
- 데이터 가용성, 신뢰성 증가
- 단점
- 소프트웨어 개발 비용 높음
- 오류의 잠재성 증대
- 처리 비용 증대
- 설계, 관리의 복합성과 비용 증가
'자격증 > SQLD' 카테고리의 다른 글
| SQLD 정리 - 2과목 SQL 활용 (0) | 2023.03.18 |
|---|---|
| SQLD 정리 - 2과목 SQL 기본 PART 2 (0) | 2023.03.14 |
| SQLD 정리 - 2과목 SQL 기본 PART 1 (0) | 2023.03.13 |
| SQLD 정리 - 1과목 데이터 모델링의 이해 정리 (0) | 2023.03.12 |




댓글