자격증 준비하면서 내가 이해하기 편하게, 다시 보기 좋게 정리하는 빅데이터 분석기사의 내용 (자격증 상세 내용은 아래)
https://www.dataq.or.kr/www/sub/a_07.do
데이터자격시험
대용량의 데이터 집합으로부터 유용한 정보를 찾고 결과를 예측하기 위해 목적에 따라 분석기술과 방법론을 기반으로 정형/비정형 대용량 데이터를 구축, 탐색, 분석하고 시각화를 수행하는 업
www.dataq.or.kr
2과목인 빅데이터 분석 기획을 정리한 내용
독립 변수
- 종속변수의 값에 영향을 미쳐 종속변수가 특정한 값을 갖게 되는 원인이 된다고 가정한 변수
- 의도적으로 변화를 시키기도 함
종속변수
- 독립변수에 영향을 받아서 변화하는 종속적인 변수
- 독립변수의 영향을 받아 그 값이 변할 것이라고 가정한 변수
변수 선택
데이터의 독립변수 중 종속변수에 가장 관련성이 높은 변수만을 선정하는 방법
- 사용자가 해석하기 쉽게 모델을 단순화해 주고 훈련 시간 축소, 차원의 저주 방지, 과적합을 줄여 일반화를 해주는 장점
- 모델의 정확도 향상 및 성능 향상 기대
변수 선택 기법
- 필터 기법 : 특정 모델링 기법에 의존하지 않고 데이터의 통계적 특성으로부터 변수를 선택하는 기법
- 래퍼 기법 : 변수의 일부만을 모델링에 사용하고 그 결과를 확인하는 작업을 반복하면서 변수를 선택해 나가는 기법
- 임베디드 기법 : 모델 자체에 변수 선택이 포함된 기법
필터 기법
- 정보이득 : 전체 엔트로피에서 분류 후 엔트로피를 뺀 값으로 불순도가 낮으면 정보 획득량이 높고, 정보 획득량이 높은 속성 선택
- 카이제곱 검정 : 관찰된 빈도가 기대되는 빈도와 의미 있게 다른지 여부를 검증하기 위해 사용되는 검증 방법
- 피셔 스코어 : 변수의 분포에 대해 유추할 수 있는 수치, 뉴턴의 방법을 사용
- 상관계수 : 두 변수 사이의 통계적 관계를 표현하기 위해 특정한 상관관계의 정도를 수치적으로 나타낸 계수
래퍼 기법
- 예측 정확도 측면에서 가장 좋은 성능을 보이는 하위 집합을 선택하는 기법
- 그 순간 최적해라고 생각되는 결정을 하는 방식인 그리디 알고리즘에 해당
- 그리디 알고리즘이므로 시간이 오래 걸리고 부하집합의 수가 기하급수적으로 늘어남
- 필터 방법보다 예측 정확도가 높음
변수 선택을 위한 알고리즘
- 전진 선택법 : 모형을 가장 많이 향상하는 변수를 하나씩 점진적으로 추가하는 방법
- 후진 소거법 : 모두 포함된 상태에서 시작하며 가장 적은 영향을 주는 변수부터 하나씩 제거
- 단계적 방법 : 전직 선택과 후진 소거를 함께 사용하는 방법
※ 기출문제

가, 나, 다 모두 옳은 설명이다. (답 : 4)

전진 선택법은 영 모형에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이 가장 큰 변수를 분석 모형에 포함시키는 것을 말한다.
후진 선택법은 전체모델에서 시작, 모든 독립변수 중 종속변수와 단순상관계수의 절댓값이 가장 작은 변수부터 순차적으로 분석 모형에서 제외시킨다.
전진 · 후진 선택법 둘 다 한번 추가된 변수에 대해서 제거하지 않는 것이 원칙이다.(답 : 4)
임베디드 기법
- 라쏘(LASSO) : 가중치의 절댓값의 합을 최소화하는 것을 추가적인 제약조건으로 하는 법 (L1-norm을 통해 제약)
- 릿지(Ridge) : 가중치들의 제곱 합을 최소화하는 것을 추가적인 제약조건으로 하는 법(L2-norm을 통해 제약)
- 엘라스틱 넷(Elastic Net) : 가중치 절댓값의 합과 제곱 합을 동시에 추가적인 제약조건으로 하는 방법(라쏘와 릿지를 선형 결합)
- SelectFromModel : 의사결정나무 기반 알고리즘에서 변수를 선택하는 방법
차원 축소
- 분석 대상이 되는 여러 변수의 정보를 최대한 유지하면서 데이터 세트 변수의 개수를 줄이는 탐색적 분석기법
- 목표변수는 사용하지 않고 특성 변수만 사용하기 때문에 비지도 학습 머신러닝 기법
차원 축소 특징
- 정보 유지 : 차원축소를 수행할 때, 축약되는 변수 세트는 원래의 전체 데이터의 변수들의 정보를 최대한 유지
- 모델 학습의 용이 : 고차원 변수보다 변환된 저 차원으로 학습할 경우, 회귀나 분류, 클러스터링 등의 머신러닝 알고리즘이 더 잘 작동
- 결과 해석의 용이 : 새로운 저 차원 변수 공간에서 시각화되기도 쉬움
- 탐색적 데이터 분석부터 정보 결과의 시각화까지 다양하게 활용
- 분석하려는 데이터가 많은 차원으로 구성되어 있을 때 좀 더 쉽게 데이터를 학습하고 모델을 생성하고자 할 때 주로 활용
- 탐색적 데이터 분석이나 텍스트 데이터에서 주제나 개념을 추출하는 데 사용
- 다차원 공간의 정보를 저차원로 시각화하거나 공통 요인을 추출하여 잠재된 데이터 규칙을 발견하기도 함
※ 기출문제

차원의 증가는 분석모델 파라미터의 증가 및 파라미터 간의 복잡한 관계의 증가로 분석결과의 과적합 발생의 가능성이 커진다. 이것은 분석모형의 정확도(신뢰도) 저하를 발생시킬 수 있다.(답 : 3)

다양한 각도에서 데이터를 살펴보는 과정을 통해 문제점의 단계에서 인지 못한 새로운 양상 · 패턴을 발견할 수 있다. 그러므로 새로운 양상을 발견 시 초기설정 문제의 가설을 수정하거나 또는 새로운 가설을 설립할 수 있다. (답 : 4)
차원축소 방법
- 변수 선택 : 가지고 있는 변수들 중에 중요한 변수만 몇 개 고르고 나머지는 버리는 방법 (상관계수가 높거나 VIF가 높은 변수 중 하나 선택)
- 변수 추출 : 모든 변수를 조합하여 데이터를 잘 표현할 수 있는 중요 성분을 가진 새로운 변수 추출
차원축소 기법
- 주성분 분석(PCA) : 원래 데이터 특징을 잘 설명해 주는 성분을 추출하기 위하여 고차원 공간의 표본들을 선형 연관성이 없는 저 차원 공간으로 변환하는 기법
- 특이값 분해(SVD) : M×N 차원의 행렬 데이터에서 특이값을 추출하고 이를 통해 주어진 데이터 세트를 효과적으로 축약할 수 있는 기법
- 요인 분석 : 모형을 세운 뒤 관찰 가능한 데이터를 이용하여 해당 잠재 요인을 도출하고 데이터 안의 구조를 해석하는 기법
- 독립성분분석(ICA) : 중선분 분석과 달리, 다변량의 신호를 통계적으로 독립적인 하부성분으로 분리하여 차원을 축소하는 기법
- 다차원 척도법(MDS) : 개체들 사이의 유사성, 비유사성을 측정하여 2차원 또는 3차원 공간 상에 점으로 표현하여 개체들 사이의 집단화를 시작적으로 표현하는 분석 방법
※ 기출문제

요인 분석의 목적에는 분포분석이 없으며 요인분석의 특성상 추론통계가 아닌 기술 통계에 의한 분석이 그 특징이다.(답 : 3)

차원 축소에 폭넓게 사용된다. 어떠한 사전적 분포 가정의 요구가 없다.
차원의 축소는 본래의 변수들이 서로 상관이 있을 때만 가능하다. (답 : 4)
파생변수
- 특정 조건 혹은 함수 등을 사용하여 새롭게 재정의한 변수
- 변수만 이용해서 분석할 수도 있지만, 변수를 조합하거나 함수를 적용해서 새 변수를 만들어 분석
파생변수 생성 방법
- 단위 변환 : 주어진 변수의 단위 혹은 척도를 변환하여 새로운 단위로 표현하는 방법
- 표현형식 변환 : 단순한 표현 방법으로 변환하는 방법
- 요약 통계량 변환 : 요약 통계량 등을 활용하여 생성하는 방법
- 정보 추출 : 하나의 변수에서 정보를 추출해서 새로운 변수를 생성하는 방법
- 변수 결합 : 다양한 함수 등 수학적 결합을 통해 새로운 변수를 정의하는 방법 (한 레코드의 값을 결합하여 파생변수 생성)
- 조건문 이용 : 조건문을 이용해서 파생변수를 생성하는 방법
※ 기출문제

특정 상황에만 유의미하지 않게 대표성을 나타나게 할 필요가 있다. (답 : 3)
변수 변환
- 박스-콕스 변환(Box-Cos)
- 데이터를 정규분포에 가깝게 만들기 위한 목적으로 사용하는 변환 방법
- λ = 0 일 때 로그 변환과 λ ≠ 0 일 때 멱 변환하는 기법
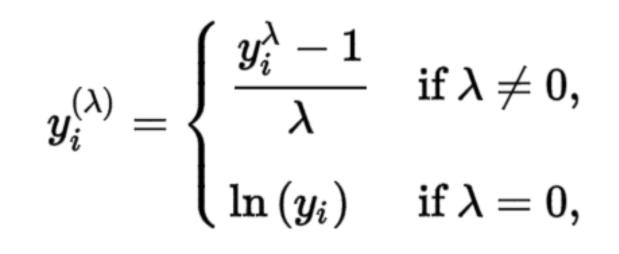

- 비닝(Binning)
- 데이터값을 몇 개의 Bin으로 분할하여 계산하는 방법
- 데이터 평활화에서도 사용되는 기술
- 정규화(Normalization)
- 정규화는 데이터를 특정 구간으로 바꾸는 척도법
- 최소-최대 정규화
- 모든 변수에 대해 최솟값은 0, 최댓값은 1로, 최솟값 및 최댓값을 제외한 다른 값들은 0과 1 사이의 값으로 변환하는 방법
- 모든 변수의 스케일이 같지만 이상값에 영향을 많이 받는 단점이 있음

- Z-점수 정규화
- 변수의 값이 평균과 일치하면 0으로 정규화되고, 평균보다 작으면 음수, 평균보다 크면 양수로 변환하는 방법
- 이상값은 잘 처리하지만, 정확히 같은 척도로 정규화된 데이터를 생성하지 못한다는 단점

※ 기출문제

로그 변환이란 어떤 수치 값을 그대로 사용하지 않고 여기에 자연로그를 취한 값을 사용하는 것을 말한다. (답 : 3)
불균형 데이터 처리
불균형한 훈련 데이터를 그대로 이용할 경우 과대 적합 문제가 발생할 수 있음
- 과소 표집
- 데이터의 소실이 매우 크고, 때로는 중요한 정상 데이터를 잃을 수 있음
- 랜덤 과소 표집 : 무작위로 다수 클래스 데이터의 일부만 선택하는 방법
- ENN(Edited Nearest Neighbor) : 소수 클래스 주위에 인접한 다수 클래스 데이터를 제거하여 데이터의 비율을 맞추는 방법
- 토멕 링크 방법 : 클래스를 구분하는 경계선 가까이에 존재하는 데이터인 토멕 링크를 제거하는 방법
- CNN(Condensed Nearest Neighbor) : 다수 클래스에 밀집된 데이터가 없을 때까지 데이터를 제거하여 데이터 분포에서 대표적인 데이터만 남도록 하는 방법
- OSS(One Sided Selection) : 토멕 링크 방법과 CNN 기법의 장점을 섞은 방법
- 과대 표집
- 정보가 손실되지 않는다는 장점이 있으나 과적합을 초래할 수 있고, 알고리즘의 성능은 높으나 검증의 성능은 나빠질 수 있음
- 랜덤 과대 표집 : 무작위로 소수 클래스 데이터를 복제하여 데이터의 비율을 맞추는 방법
- SMOTE : 소수 클래스에서 중심이 되는 데이터와 주변 데이터 사이에 가상의 직선을 만든 후, 그 위에 데이터를 추가하는 방법
- Borderline - SMOTE : 다수 클래스와 소수 클래스의 경계선에서 SMOTE를 적용하는 방법
- ADASYN : 모든 소수 클래스에서 다수 클래스의 관측비율을 계산하여 SMOTE를 적용하는 방법
- 임계값 이동
- 임계값을 데이터가 많은 쪽으로 이동시키는 방법
- 학습 단계에서는 변화 없이 학습하고 테스트 단계에서 임계값을 이동
- 앙상블 기법
- 같거나 서로 다른 여러 가지 모형들의 예측/분류 결과를 종합하여 최종적인 의사 결정에 활용하는 기법
- 앙상블 알고리즘은 여러 개의 학습 모델을 훈련하고 투표 및 평균을 통해 최적화된 예측을 수행하고 결정
- 다중 모델 조합, 분류기 조합이 있음
- 과소 표집, 과대 표집, 임계값 이동을 조합하여 앙상블을 만들 수 있음
※ 기출문제

데이터에서 각 클래스가 갖고 있는 데이터의 양에 차이가 큰 경우, 클래스 불균형이 있다고 말한다 (답 : 4)
뒤로 이어지는 내용
https://edder773.tistory.com/137
[빅데이터 분석 기사 필기 2과목] 빅데이터 탐색 정리 - 3
자격증 준비하면서 내가 이해하기 편하게, 다시 보기 좋게 정리하는 빅데이터 분석기사의 내용 (자격증 상세 내용은 아래) https://www.dataq.or.kr/www/sub/a_07.do 데이터자격시험 대용량의 데이터 집합
edder773.tistory.com
'자격증 > 빅데이터 분석 기사' 카테고리의 다른 글
| [빅데이터 분석 기사 필기 2과목] 빅데이터 탐색 정리 - 4 (0) | 2023.04.04 |
|---|---|
| [빅데이터 분석 기사 필기 2과목] 빅데이터 탐색 정리 - 3 (0) | 2023.04.04 |
| [빅데이터 분석 기사 필기 2과목] 빅데이터 탐색 정리 - 1 (0) | 2023.04.04 |
| [빅데이터 분석 기사 필기 1과목] 빅데이터 분석 기획 정리 - 6 (0) | 2023.04.03 |
| [빅데이터 분석 기사 필기 1과목] 빅데이터 분석 기획 정리 - 5 (0) | 2023.04.03 |




댓글