자격증 준비하면서 내가 이해하기 편하게, 다시 보기 좋게 정리하는 정보처리기사의 내용 (자격증 상세 내용은 아래)
http://www.q-net.or.kr/crf005.do?id=crf00505&gSite=Q&gId=
http://www.q-net.or.kr/crf005.do?gId=&gSite=Q&id=crf00505
www.q-net.or.kr
데이터베이스와 관계형 데이터베이스의 개요 부분을 정리한 내용
데이터 전환
- ETL(추출, 변환, 적재)을 하는 과정
- 데이터 이행 또는 데이터 이관이라고도 함
데이터 전환 계획서
- 데이터 전환 작업에 필요한 모든 계획을 기록하는 문서
- 주요 항목 : 데이터 전환 개요, 데이터 전환 대상 및 범위, 데이터 전환 환경 구성 등
데이터 검증 방법
- 로그 검증 : 데이터 전환 과정에서 작성하는 추출, 전환, 적재 로그 검증
- 기본 항목 검증 : 로그 검증 외에 별도로 요청된 검증 항목에 대해 검증
- 응용 프로그램 검증 : 응용 프로그램을 통한 데이터 전환의 정합성 검증
- 응용 데이터 검증 : 사전에 정의된 업무 규칙을 기준으로 데이터 전환의 정합성을 검증
- 값 검증 : 숫자 항목의 합계 검증, 코드 데이터의 범위 검증, 속성 변경에 따른 값 검증
데이터 검증 단계
- 추출 : 원천 시스템에 대한 정합성 확인 (로그 검증)
- 전환 : 매핑 정의서에 정의된 내용이 정확히 반영되었는지 확인 (로그 검증)
- DB 적재 : SAM 파일을 적재하는 과정에서 발생할 수 있는 오류나 데이터 누락 여부 확인 (로그 검증)
- DB 적재 후 : 적재 완료 후 정합성 확인 (기본 항목 검증)
- 전환 완료 후 : 데이터 전환 완료 후 추가 검증 과정을 통해 데이터 전환의 정합성 검증 (응용 프로그램 검증, 응용 데이터 검증)
오류 데이터 측정 및 정제
- 데이터 품질 분석 -> 오류 데이터 측정 → 오류 데이터 정제
- 데이터 품질 분석 : 오류 데이터를 찾기 위해 원천 및 목적 시스템의 데이터의 정합성 여부를 확인하는 작업
- 오류 데이터 측정 : 데이터 품질 분석을 기반으로 정상 데이터와 오류 데이터의 수를 측정하여 오류 관리 목록을 작성
- 오류 데이터 정제 : 오류 관리 목록의 각 항목을 분석하여 원천 데이터를 정제하거나 전환 프로그램을 수정
오류 상태
- Open : 오류가 보고만 되고 분석되지 않는 상태
- Assigned : 오류으,ㅣ 영향 분석 및 수정을 위해 개발자에게 오류를 전달한 상태
- Fixed : 개발자가 오류를 수정한 상태
- Closed : 수정된 오류에 대해 테스트를 다시 했을 때 오류가 발견되지 않은 상태
- Deferred : 오류 수정을 연기한 상태
- Clarified(Classified) : 보고된 오류를 관련자들이 확인했을 때 오류가 아니라고 확인된 상태
데이터베이스
- 공동으로 사용될 데이터를 중복을 배제하여 통합하고, 저장장치에 저장하여 항상 사용할 수 있도록 운영하는 운영 데이터
- 통합된 데이터 : 자료의 중복을 배제한 데이터의 모임
- 저장된 데이터 : 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
- 운영 데이터 : 조직의 고유한 업무를 수행하는 데 반드시 필요한 자료
- 고영 데이터 : 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
DBMS(데이터베이스 관리 시스템)
- 사용자의 요구에 따라 정보를 생성해 주고, 데이터베이스를 관리해 주는 소프트웨어
- 정의 기능 : 데이터의 형과 구조에 대한 정의, 이용 방식, 제약 조건 등을 명시하는 기능
- 조작 기능 : 데이터 검색, 갱신, 삽입, 삭제 등을 위해 인터페이스 수단을 제공하는 기능
- 제어 기능 : 데이터의 무결성, 보안, 권한 검사, 병행 제어를 제공하는 기능
데이터 독립성
- 논리적 독립성 : 응용 프로그램과 데이터베이스를 독립시킴으로써, 데이터의 논리적 구조를 변경시키더라도 응용 프로그램은 영향을 받지 않음
- 물리적 독립성 : 응용 프로그램과 보조기억장치 같은 물리적 장치를 독립시킴으로써 디스크를 추가 및 변경하더라도 응용 프로그램은 영향받지 않음
스키마
- 외부 스키마 : 사용자나 응용 프로그래머가 각 개인의 입장에서 필요로 하는 데이터 베이스의 논리적 구조를 정의한 것
- 개념 스키마 : 데이터베이스의 전체적인 논리 구조로 모든 응용 프로그램이나 사용자들이 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스
- 내부 스키마 : 물리적 저장장치의 입장에서 본 데이터베이스 구조로 실제 저장될 레코드의 형식, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 표시
데이터베이스 설계 시 고려사항
- 무결성 : 삽입, 삭제, 갱신 등의 연산 후에도 데이터베이스에 저장된 데이터가 정해진 제약 조건을 항상 만족해야 함
- 일관성 : 데이터베이스에 저장된 데이터들 사이나, 특정 질의에 대한 응답이 처음부터 끝까지 변함없이 일정해야 함
- 회복 : 시스템에 장애가 발생했을 때 장애 발생 직전의 상태로 복구할 수 있어야 함
- 보안 : 불법적인 데이터의 노출 또는 변경이나 손실로부터 보호할 수 있어야 함
- 효율성 : 응답시간의 단축, 시스템의 생산성, 저장 공간의 최적화 등이 가능해야 함
- 데이터베이스 확장 : 데이터베이스를 운영에 영향을 주지 않으면서 지속적으로 데이터를 추가할 수 있어야 함
데이터베이스 설계 순서
- 요구 조건 분석 : 요구 조건 명세서 작성
- 개념적 설계 : 개념 스키마, 트랜잭션 모델링, E-R 모델
- 논리적 설계 : 목표 DBMS에 맞는 논리 스키마 설계, 트랜잭션 인터페이스 설계
- 물리적 설계 : 목표 DBMS에 맞는 물리적 구조의 데이터로 변환
- 구현 : 목표 DBMS의 DDL로 데이터베이스 생성, 트랜잭션 작성
요구 조건 분석
- 데이터베이스를 사용할 사람들로부터 필요한 용도를 파악하는 것
- 데이터베이스 사용자에 따른 수행 업무와 필요한 데이터의 종류, 용도, 처리 형태, 흐름, 제약 조건 등을 수집
개념적 설계(정보 모델링, 개념화)
- 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- DBMS에 독립적인 E-R 다이어그램으로 작성
- DBMS에 독립적인 개념 스키마 설계
논리적 설계(데이터 모델링)
- 현실 세계에서 발생하는 자료를 특정 DBMS가 지원하는 논리적 자료 구조로 변환시키는 과정
- 트랜잭션의 인터페이스 설계
물리적 설계(데이터 구조화)
- 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
- 저장 레코드의 형식, 순서, 접근 경로, 조회 집중 레코드 등의 정보를 사용하여 데이터가 컴퓨터에 저장되는 방법 묘사
데이터베이스 구현
- 논리적 설계와 물리적 설계에서 도출된 데이터베이스 스키마를 파일로 생성하는 과정
- DBMS의 DDL을 이용하여 데이터베이스 스키마를 기술한 후 컴파일하여 빈 데이터베이스 파일 생성
데이터 모델
- 현실 세계의 정보들을 체계적으로 표현한 개념적 모형으로 개체, 속성, 관계로 구성
- 개념적 데이터 모델
- 현실 세계에 대한 인간의 이해를 돕기 위해 현실 세계에 대한 인식을 추상적 개념으로 표현하는 과정
- 대표적으로 E-R모델
- 논리적 데이터 모델
- 개념적 구조를 컴퓨터 세계의 환경에 맞도록 변환하는 과정
- 데이터 간의 관계를 어떻게 표현하느냐에 따라 관계 모델, 계층 모델, 네트워크 모델로 구분
- 데이터 모델 표시 요소
- 구조 : 논리적으로 표현된 개체 타입들 간의 관계로서 데이터 구조 및 정적 성질 표현
- 연산 : 데이터베이스에 저장된 실제 데이터를 처리하는 작업에 대한 명세로서 데이터베이스를 조작하는 기본 도구
- 제약 조건 : 데이터베이스에 저장될 수 있는 실제 데이터의 논리적인 제약 조건
데이터 모델 구성 요소
- 개체 : 데이터베이스에 표현하려는 것으로 개념이나 정보 단위 같은 현실 세계의 대상체
- 속성 : 데이터베이스를 구성하는 가장 작은 논리적 단위 (속성의 수 = 디그리 (차수))
- 특성에 따른 속성 분류
- 기본 속성 : 업무 분석을 통해 정의한 속성으로 가장 많고 일반적
- 설계 속성 : 원래 업무상 존재하지 않고 설계 과정에서 도출해 내는 속성으로 데이터 모델링을 위해 업무를 규칙화하려고 정의하는 속성
- 파생 속성 : 다른 속성으로부터 계산이나 변현 등의 영향을 받아 발생하는 속성
- 속성의 개체 구성 방식에 따른 분류
- 기본키 속성 : 개체를 유일하게 식별할 수 있는 속성
- 외래키 속성 : 다른 개체와의 관계에서 포함된 속성
- 일반 속성 : 개체에 포함되어 있고 기본키, 외래키에 포함되지 않은 속성
- 특성에 따른 속성 분류
- 관계 : 개체와 개체 사이의 논리적인 연결
- 관계 형태
- 일 대 일 (1:1) : 집합 A의 각 원소가 집합 B의 원소 한 개와 대응하는 관계
- 일 대 다 (1:N) : 집합 A의 각 원소는 집합 B의 원소 여러 개와 대응하지만, 집합 B의 각 원소는 집합 A의 원소 한 개와 대응하는 관계
- 다 대 다 (N:M) : 집합 A의 각 원소는 집합 B의 원소 여러 개와 대응하고, 집합 B의 각 원소 집합 A의 원소 여러 개와 대응하는 관계
- 관계 종류
- 종속 관계 : 두 개체 사이의 주종 관계를 표현한 것으로 식별, 비식별 관계가 있음
- 중복 관계 : 두 개체 사이에 2번 이상의 종속 관계가 발생하는 관계
- 재귀 관계 : 개체가 자기 자신과 관계를 갖는 것
- 배타 관계 : 개체의 속성이나 구분자를 기준으로 개체의 특성을 분할하는 관계로 배타 AND, 배타 OR 관계로 구분
- 관계 형태
식별자
- 하나의 개체 내에서 각각의 인스턴스를 유일하게 구분할 수 있는 구분자
- 모든 개체는 한 개 이상의 식별자를 가져야 함
식별자의 분류
- 대표성 여부
- 주 식별자 : 개체를 대표하는 유일한 식별자
- 보조 식별자 : 주 식별자를 대신하여 개체를 식별할 수 있는 속성
- 스스로 생성 여부
- 내부 식별자 : 개체 내에서 스스로 만들어지는 식별자
- 외부 식별자 : 다른 개체와의 관계에 의해 외부 개체의 식별자를 가져와 사용하는 식별자
- 단일 속성 여부
- 단일 식별자 : 주 식별자가 한 가지 속성으로만 구성된 식별자
- 복합 식별자 : 주 식별자가 두 개 이상의 속성으로 구성된 식별자
- 대체 여부
- 원조 식별자 : 업무에 의해 만들어지는 가공되지 않은 원래의 식별자
- 대리 식별자 : 주 식별자의 속성이 두 개 이상인 경우 속성들을 하나의 속성으로 묶어 사용하는 식별자
후보 식별자
- 개체에서 각 인스턴스를 유일하게 식별할 수 있는 속성 또는 속성 집합
- 하나의 개체에는 한 개 이상의 후보 식별자가 존재할 수 있고, 개체의 대표성을 나타내는 식별자를 주식별자, 나머지는 보조 식별자로 지정
주 식별자 특징
- 유일성 : 개체 내의 모든 인스턴스들은 주 식별자에 의해 유일하게 구분되어야 함
- 최소성 : 유일성을 만족시키기에 필요한 최소한의 속성으로만 구성
- 불변성 : 주 식별자가 특정 개체에 한 번 지정되면 그 식별자는 변하지 않아야 함
- 존재성 : 주 식별자가 지정되면 식별자 속성에 반드시 데이터 값이 존재
E-R(개체-관계) 모델 다이어그램
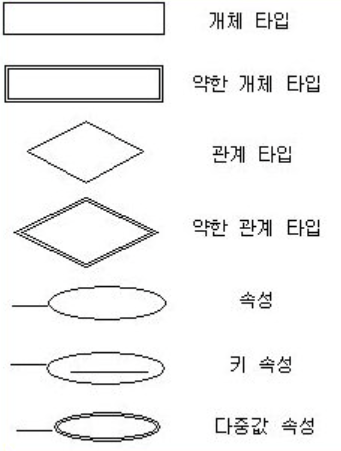
관계형 데이터베이스
- 2차원적인 표를 이용해서 데이터 상호 관계를 정의하는 데이터베이스
- 간결하고 보기 편리하며, 다른 데이터베이스로의 변환이 용이함
- 다만 성능이 다소 떨어짐
튜플
- 릴레이션을 구성하는 각각의 행
- 튜플의 수를 카디널리티, 기수, 대응수라고도함
속성
- 데이터베이스를 구성하는 가장 작은 논리적 단위
- 속성의 수를 디그리, 차수라고도 함
도메인
하나의 속성이 취할 수 있는 같은 타입의 원자의 집합
릴레이션의 특징
- 한 릴레이션에는 똑같은 튜플이 포함될 수 없으므로 릴레이션에 포함된 튜플들은 모두 상이
- 한 릴레이션에 포함된 튜플 사이에 순서가 없음
- 릴레이션을 구성하는 튜플을 유일하게 식별하기 위해 속성들의 부분집합을 키로 설정
- 속성의 값은 논리적으로 더 이상 쪼갤 수 없는 원자값만을 저장
관계형 데이터 모델
- 2차원적인 표를 이용해서 데이터 상호 관계를 정의하는 DB구조
- 기본키와 이를 참조하는 외래키로 데이터 간의 관계를 표현
- 대표적으로 SQL언어 사용
후보키
- 속성들 중에서 튜플을 유일하게 식별하기 위해 사용하는 속성들의 부분집합
- 유일성 : 하나의 키 값으로 하나의 튜플만을 유일하게 식별할 수 있어야 함
- 최소성 : 키를 구성하는 속성 하나를 제거하면 유일하게 식별할 수 없도록 꼭 필요한 최소의 속성으로 구성
기본키
- 후보키 중에서 특별히 선정된 주 키
- 중복된 값을 가질 수 없음
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- NULL값을 가질 수 없음
대체키
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키
- 보조키라고도함
슈퍼키
- 속성들의 집합으로 구성된 키
- 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족하지 못함
외래키
- 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합을 의미
- 외래키로 지정되면 참조 릴레이션의 기본키에 없는 값은 입력 불가
무결성
- 데이터베이스에 저장된 데이터 값과 현실세계의 실제값이 일치하는 정확성
- 개체 무결성 : 기본 테이블의 기본키를 구성하는 어떤 속성도 Null 값이나 중복값을 가질 수 없음
- 참조 무결성 : 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 함
- 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다는 규정
- 사용자 정의 무결성 : 속성 값들이 사용자가 정의한 제약조건에 만족되어야 한다는 규정
- Null 무결성 ; 릴레이션의 특정 속성 값이 Null이 될 수 없도록 하는 규정
- 고유 무결성 : 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성값들이 서로 달라야 한다는 규정
- 키 무결성 : 하나의 릴레이션에는 적어도 하나의 키가 존재해야 한다는 규정
- 관계 무결성 : 릴레이션에 어느 한 튜플의 삽입 가능 여부 또는 한 릴레이션과 다른 릴레이션의 튜플들 사이의 관계에 대한 적절성 여부를 지정한 규정
데이터 무결성 강화
- 애플리케이션 ; 데이터 생성, 수정, 삭제 시 무결성 조건을 검증하는 코드를 프로그램 내에 추가
- 데이터베이스 트리거 : 트리거 이벤트에 무결성 조건을 실행하는 절차형 SQL을 추가
- 제약 조건 : 데이터베이스에 제약 조건을 설정하여 무결성을 유지
관계대수
- 원하는 정보와 그 정보를 검색하기 위해서 어떻게 유도하는가를 기술하는 절차적 언어
- 릴레이션을 처리하기 위해 연산자와 연산 규칙을 제공하며, 피연산자와 연산 결과가 모두 릴레이션
순수 관계 연산자
Select : 릴레이션에 존재하는 튜플 중에서 선택 조건을 만족하는 튜플의 부분집합을 구하여 새로운 릴레이션을 만드는 연산 (기호 : σ)
Project : 주어진 릴레이션에서 속성 리스트에 제시된 속성 값만을 추출하여 새로운 릴레이션을 만드는 연산 (기호 : π)
Join 공통 속성을 중심으로 두 개의 릴레이션을 하나로 합쳐서 새로운 릴레이션을 만드는 연산 (기호 : ▷◁)
Division : X ⊃ Y인 두 개의 릴레이션 R(X)와 S(Y)가 있을 때, R의 속성이 S의 속성값을 모두 가진 튜플에서 S가 가진 속성을 제외한 속성만을 구하는 연산
일반 집합 연산자
- 합집합(UNION ∪)
- 두 릴레이션에 존재하는 튜플의 합집합을 구하되, 결과로 생성된 릴레이션에서 중복되는 튜플은 제거되는 연산
- 카디널리티 : |R∪S| ≤ |R| + |S|
- 교집합(INTERSECTION, ∩)
- 두 릴레이션에 존재하는 튜플의 교집합을 구하는 연산
- 카디널리티 |R∩S| ≤ min(|R|,|S|)
- 차집합 (DIFFERENCE, -)
- 두 릴레이션에 존재하는 튜플의 차집합을 구하는 연산
- 카디널리티 |R-S| ≤ |R|
- 교차곱
- 두 릴레이션에 있는 튜플들의 순서쌍을 구하는 연산
- |R×S| = |R| × |S|
관계 해석
- 관계 데이터의 연산을 표현하는 방법
- E.F.Codd가 수학의 술어 해석에 기반을 두고 관계 데이터베이스를 위해 제안
뒤로 이어지는 내용
https://edder773.tistory.com/181
[정보처리기사 실기] 정규화 및 데이터베이스 보안 정리
자격증 준비하면서 내가 이해하기 편하게, 다시 보기 좋게 정리하는 정보처리기사의 내용 (자격증 상세 내용은 아래) http://www.q-net.or.kr/crf005.do?id=crf00505&gSite=Q&gId= http://www.q-net.or.kr/crf005.do?gId=&gSit
edder773.tistory.com
'자격증 > 정보처리기사' 카테고리의 다른 글
| [정보처리기사 실기] 통합 구현 정리 (0) | 2023.04.16 |
|---|---|
| [정보처리기사 실기] 자료구조와 정렬 정리 (0) | 2023.04.16 |
| [정보처리기사 실기] 정규화 및 데이터베이스 보안 정리 (0) | 2023.04.16 |
| [정보처리기사 실기] 비용 산정 기법 & 소프트웨어 개발 정리 (0) | 2023.04.12 |
| [정보처리기사 실기] 요구사항 및 UML 정리 (0) | 2023.04.11 |




댓글